Interaction Between PL/SQL and Oracle
Knowledge is of two kinds. We know a subject ourselves, or we know where we can find information upon it. --Samuel Johnson
This chapter helps you harness the power of Oracle. You
learn how PL/SQL supports the SQL commands, functions, and operators
that let you manipulate Oracle data. You also learn how to manage
cursors, use cursor variables, and process transactions.
This chapter discusses the following topics:
- Overview of SQL Support in PL/SQL
- Managing Cursors
- Separating Cursor Specs and Bodies with Packages
- Using Cursor FOR Loops
- Using Cursor Variables
- Using Cursor Attributes
- Using Cursor Expressions
- Overview of Transaction Processing in PL/SQL
- Doing Independent Units of Work with Autonomous Transactions
- Ensuring Backward Compatibility of PL/SQL Programs
Overview of SQL Support in PL/SQL
By extending SQL, PL/SQL offers a unique combination of
power and ease of use. You can manipulate Oracle data flexibly and
safely because PL/SQL fully supports all SQL data manipulation
statements (except
EXPLAIN PLAN), transaction
control statements, functions, pseudocolumns, and operators. PL/SQL also
supports dynamic SQL, which enables you to execute SQL data definition,
data control, and session control statements dynamically. In addition,
PL/SQL conforms to the current ANSI/ISO SQL standard.Data Manipulation
To manipulate Oracle data, you use the
INSERT, UPDATE, DELETE, SELECT, and LOCK TABLE commands. INSERT adds new rows of data to database tables; UPDATE modifies rows; DELETE removes unwanted rows; SELECT retrieves rows that meet your search criteria; and LOCK TABLE temporarily limits access to a table.Transaction Control
Oracle is transaction oriented; that is, Oracle uses transactions to ensure data integrity. A transaction is a series of SQL data manipulation statements that does a logical unit of work. For example, two
UPDATE statements might credit one bank account and debit another.
Simultaneously, Oracle makes permanent or undoes all
database changes made by a transaction. If your program fails in the
middle of a transaction, Oracle detects the error and rolls back the
transaction. Thus, the database is restored to its former state
automatically.
You use the
COMMIT, ROLLBACK, SAVEPOINT, and SET TRANSACTION commands to control transactions. COMMIT makes permanent any database changes made during the current transaction. ROLLBACK ends the current transaction and undoes any changes made since the transaction began. SAVEPOINT marks the current point in the processing of a transaction. Used with ROLLBACK, SAVEPOINT undoes part of a transaction. SET TRANSACTION sets transaction properties such as read/write access and isolation level.SQL Functions
PL/SQL lets you use all the SQL functions including the
following aggregate functions, which summarize entire columns of Oracle
data:
AVG, COUNT, GROUPING, MAX, MIN, STDDEV, SUM, and VARIANCE. Except for COUNT(*), all aggregate functions ignore nulls.
You can use the aggregate functions in SQL statements, but not in procedural statements. Aggregate functions operate on entire columns unless you use the
SELECT GROUP BY statement to sort returned rows into subgroups. If you omit the GROUP BY clause, the aggregate function treats all returned rows as a single group.
You call an aggregate function using the syntax
function_name([ALL | DISTINCT] expression)
where
expression refers to one or more database columns. If you specify ALL (the default), the aggregate function considers all column values including duplicates. If you specify DISTINCT,
the aggregate function considers only distinct values. For example, the
following statement returns the number of different job titles in the
database table emp:SELECT COUNT(DISTINCT job) INTO job_count FROM emp;
The function
COUNT lets you use the asterisk (*)
row operator, which returns the number of rows in a table. For example,
the following statement returns the number of rows in table emp:SELECT COUNT(*) INTO emp_count FROM emp;
SQL Pseudocolumns
PL/SQL recognizes the following SQL pseudocolumns, which return specific data items:
CURRVAL, LEVEL, NEXTVAL, ROWID, and ROWNUM.
Pseudocolumns are not actual columns in a table but they behave like
columns. For example, you can select values from a pseudocolumn.
However, you cannot insert into, update, or delete from a pseudocolumn.
Also, pseudocolumns are allowed in SQL statements, but not in procedural statements.CURRVAL and NEXTVAL
A sequence is a schema object that
generates sequential numbers. When you create a sequence, you can
specify its initial value and an increment.
CURRVAL returns the current value in a specified sequence.
Before you can reference
CURRVAL in a session, you must use NEXTVAL to generate a number. A reference to NEXTVAL stores the current sequence number in CURRVAL. NEXTVAL
increments the sequence and returns the next value. To obtain the
current or next value in a sequence, you must use dot notation, as
follows:sequence_name.CURRVAL sequence_name.NEXTVAL
After creating a sequence, you can use it to generate unique sequence numbers for transaction processing. However, you can use
CURRVAL and NEXTVAL only in a SELECT list, the VALUES clause, and the SET clause. In the following example, you use a sequence to insert the same employee number into two tables:INSERT INTO emp VALUES (empno_seq.NEXTVAL, my_ename, ...); INSERT INTO sals VALUES (empno_seq.CURRVAL, my_sal, ...);
If a transaction generates a sequence number, the sequence
is incremented immediately whether you commit or roll back the
transaction.
LEVEL
You use
LEVEL with the SELECT CONNECT BY statement to organize rows from a database table into a tree structure. LEVEL
returns the level number of a node in a tree structure. The root is
level 1, children of the root are level 2, grandchildren are level 3,
and so on.
In the
START WITH clause, you
specify a condition that identifies the root of the tree. You specify
the direction in which the query walks the tree (down from the root or
up from the branches) with the PRIOR operator.ROWID
ROWID returns the rowid (binary address) of a row in a database table. You can use variables of type UROWID to store rowids in a readable format. In the following example, you declare a variable named row_id for that purpose:DECLARE row_id UROWID;
When you select or fetch a physical rowid into a
UROWID variable, you can use the function ROWIDTOCHAR, which converts the binary value to an 18-byte character string. Then, you can compare the UROWID variable to the ROWID pseudocolumn in the WHERE clause of an UPDATE or DELETE statement to identify the latest row fetched from a cursor. For an example, see "Fetching Across Commits".ROWNUM
ROWNUM returns a number indicating the order in which a row was selected from a table. The first row selected has a ROWNUM of 1, the second row has a ROWNUM of 2, and so on. If a SELECT statement includes an ORDER BY clause, ROWNUMs are assigned to the retrieved rows before the sort is done.
You can use
ROWNUM in an UPDATE statement to assign unique values to each row in a table. Also, you can use ROWNUM in the WHERE clause of a SELECT statement to limit the number of rows retrieved, as follows:DECLARE CURSOR c1 IS SELECT empno, sal FROM emp WHERE sal > 2000 AND ROWNUM < 10; -- returns 10 rows
The value of
ROWNUM increases only when a row is retrieved, so the only meaningful uses of ROWNUM in a WHERE clause are... WHERE ROWNUM < constant; ... WHERE ROWNUM <= constant;
SQL Operators
PL/SQL lets you use all the SQL comparison, set, and row
operators in SQL statements. This section briefly describes some of
these operators. For more information, see Oracle9i SQL Reference.
Comparison Operators
Typically, you use comparison operators in the
WHERE clause of a data manipulation statement to form predicates, which compare one expression to another and always yield TRUE, FALSE, or NULL.
You can use all the comparison operators listed below to form
predicates. Moreover, you can combine predicates using the logical
operators AND, OR, and NOT.Set Operators
Set operators combine the results of two queries into one result.
INTERSECT returns all distinct rows selected by both queries. MINUS returns all distinct rows selected by the first query but not by the second. UNION returns all distinct rows selected by either query. UNION ALL returns all rows selected by either query, including all duplicates.Row Operators
Row operators return or reference particular rows.
ALL retains duplicate rows in the result of a query or in an aggregate expression. DISTINCT eliminates duplicate rows from the result of a query or from an aggregate expression. PRIOR refers to the parent row of the current row returned by a tree-structured query.Managing Cursors
PL/SQL uses two types of cursors: implicit and explicit.
PL/SQL declares a cursor implicitly for all SQL data manipulation
statements, including queries that return only one row. However, for
queries that return more than one row, you must declare an explicit
cursor, use a cursor
FOR loop, or use the BULK COLLECT clause.Overview of Explicit Cursors
The set of rows returned by a query can consist of zero,
one, or multiple rows, depending on how many rows meet your search
criteria. When a query returns multiple rows, you can explicitly declare
a cursor to process the rows. Moreover, you can declare a cursor in the
declarative part of any PL/SQL block, subprogram, or package.
You use three commands to control a cursor:
OPEN, FETCH, and CLOSE. First, you initialize the cursor with the OPEN statement, which identifies the result set. Then, you can execute FETCH repeatedly until all rows have been retrieved, or you can use the BULK COLLECT clause to fetch all rows at once. When the last row has been processed, you release the cursor with the CLOSE statement. You can process several queries in parallel by declaring and opening multiple cursors.Declaring a Cursor
Forward references are not allowed in PL/SQL. So, you must
declare a cursor before referencing it in other statements. When you
declare a cursor, you name it and associate it with a specific query
using the syntax
CURSOR cursor_name [(parameter[, parameter]...)] [RETURN return_type] IS select_statement;
where
return_type must represent a record or a row in a database table, and parameter stands for the following syntax:cursor_parameter_name [IN] datatype [{:= | DEFAULT} expression]
For example, you might declare cursors named
c1 and c2, as follows:DECLARE CURSOR c1 IS SELECT empno, ename, job, sal FROM emp WHERE sal > 2000; CURSOR c2 RETURN dept%ROWTYPE IS SELECT * FROM dept WHERE deptno = 10;
The cursor name is an undeclared identifier, not the name
of a PL/SQL variable. You cannot assign values to a cursor name or use
it in an expression. However, cursors and variables follow the same
scoping rules. Naming cursors after database tables is allowed but not
recommended.
A cursor can take parameters, which can appear in the
associated query wherever constants can appear. The formal parameters of
a cursor must be
IN parameters. Therefore, they cannot return values to actual parameters. Also, you cannot impose the constraint NOT NULL on a cursor parameter.
As the example below shows, you can initialize cursor
parameters to default values. That way, you can pass different numbers
of actual parameters to a cursor, accepting or overriding the default
values as you please. Also, you can add new formal parameters without
having to change every reference to the cursor.
DECLARE CURSOR c1 (low INTEGER DEFAULT 0, high INTEGER DEFAULT 99) IS SELECT ...
The scope of cursor parameters is local to the cursor,
meaning that they can be referenced only within the query specified in
the cursor declaration. The values of cursor parameters are used by the
associated query when the cursor is opened.
Opening a Cursor
Opening the cursor executes the query and identifies the
result set, which consists of all rows that meet the query search
criteria. For cursors declared using the
FOR UPDATE clause, the OPEN statement also locks those rows. An example of the OPEN statement follows:DECLARE CURSOR c1 IS SELECT ename, job FROM emp WHERE sal < 3000; ... BEGIN OPEN c1; ... END;
Rows in the result set are not retrieved when the
OPEN statement is executed. Rather, the FETCH statement retrieves the rows.Passing Cursor Parameters
You use the
OPEN statement to pass parameters
to a cursor. Unless you want to accept default values, each formal
parameter in the cursor declaration must have a corresponding actual
parameter in the OPEN statement. For example, given the cursor declarationDECLARE emp_name emp.ename%TYPE; salary emp.sal%TYPE; CURSOR c1 (name VARCHAR2, salary NUMBER) IS SELECT ...
any of the following statements opens the cursor:
OPEN c1(emp_name, 3000); OPEN c1('ATTLEY', 1500); OPEN c1(emp_name, salary);
In the last example, when the identifier
salary is used in the cursor declaration, it refers to the formal parameter. But, when it is used in the OPEN statement, it refers to the PL/SQL variable. To avoid confusion, use unique identifiers.
Formal parameters declared with a default value need not
have a corresponding actual parameter. They can simply assume their
default values when the
OPEN statement is executed.
You can associate the actual parameters in an
OPEN
statement with the formal parameters in a cursor declaration using
positional or named notation. The datatypes of each actual parameter and
its corresponding formal parameter must be compatible.Fetching with a Cursor
Unless you use the
BULK COLLECT clause (discussed in the next section), the FETCH
statement retrieves the rows in the result set one at a time. Each
fetch retrieves the current row and then advances the cursor to the next
row in the result set. An example follows:FETCH c1 INTO my_empno, my_ename, my_deptno;
For each column value returned by the query associated
with the cursor, there must be a corresponding, type-compatible variable
in the
INTO list. Typically, you use the FETCH statement in the following way:LOOP FETCH c1 INTO my_record; EXIT WHEN c1%NOTFOUND; -- process data record END LOOP;
The query can reference PL/SQL variables within its scope.
However, any variables in the query are evaluated only when the cursor
is opened. In the following example, each retrieved salary is multiplied
by
2, even though factor is incremented after every fetch:DECLARE my_sal emp.sal%TYPE; my_job emp.job%TYPE; factor INTEGER := 2; CURSOR c1 IS SELECT factor*sal FROM emp WHERE job = my_job; BEGIN ... OPEN c1; -- here factor equals 2 LOOP FETCH c1 INTO my_sal; EXIT WHEN c1%NOTFOUND; factor := factor + 1; -- does not affect FETCH END LOOP; END;
To change the result set or the values of variables in the
query, you must close and reopen the cursor with the input variables
set to their new values.
However, you can use a different
INTO list on
separate fetches with the same cursor. Each fetch retrieves another row
and assigns values to the target variables, as the following example
shows:DECLARE CURSOR c1 IS SELECT ename FROM emp; name1 emp.ename%TYPE; name2 emp.ename%TYPE; name3 emp.ename%TYPE; BEGIN OPEN c1; FETCH c1 INTO name1; -- this fetches first row FETCH c1 INTO name2; -- this fetches second row FETCH c1 INTO name3; -- this fetches third row ... CLOSE c1; END;
If you fetch past the last row in the result set, the values of the target variables are indeterminate.
Note: Eventually, the
FETCH
statement must fail to return a row, so when that happens, no exception
is raised. To detect the failure, you must use the cursor attribute %FOUND or %NOTFOUND. For more information, see "Using Cursor Attributes"Fetching Bulk Data with a Cursor
The
BULK COLLECT clause lets you bulk-bind entire columns of Oracle data (see "Retrieving Query Results into Collections with the BULK COLLECT Clause").
That way, you can fetch all rows from the result set at once. In the
following example, you bulk-fetch from a cursor into two collections:DECLARE TYPE NumTab IS TABLE OF emp.empno%TYPE; TYPE NameTab IS TABLE OF emp.ename%TYPE; nums NumTab; names NameTab; CURSOR c1 IS SELECT empno, ename FROM emp WHERE job = 'CLERK'; BEGIN OPEN c1; FETCH c1 BULK COLLECT INTO nums, names; ... CLOSE c1; END;
Closing a Cursor
The
CLOSE statement disables the cursor, and
the result set becomes undefined. Once a cursor is closed, you can
reopen it. Any other operation on a closed cursor raises the predefined
exception INVALID_CURSOR.Using Subqueries in Cursors
A subquery is a query (usually
enclosed by parentheses) that appears within another SQL data
manipulation statement. When evaluated, the subquery provides a value or
set of values to the statement. Often, subqueries are used in the
WHERE clause. For example, the following query returns employees not located in Chicago:DECLARE CURSOR c1 IS SELECT empno, ename FROM emp WHERE deptno IN (SELECT deptno FROM dept WHERE loc <> 'CHICAGO');
Using a subquery in the
FROM clause, the following query returns the number and name of each department with five or more employees:DECLARE CURSOR c1 IS SELECT t1.deptno, dname, "STAFF" FROM dept t1, (SELECT deptno, COUNT(*) "STAFF" FROM emp GROUP BY deptno) t2 WHERE t1.deptno = t2.deptno AND "STAFF" >= 5;
Whereas a subquery is evaluated only once for each table, a correlated subquery
is evaluated once for each row. Consider the query below, which returns
the name and salary of each employee whose salary exceeds the
departmental average. For each row in the
emp table, the
correlated subquery computes the average salary for that row's
department. The row is returned if that row's salary exceeds the
average.DECLARE CURSOR c1 IS SELECT deptno, ename, sal FROM emp t WHERE sal > (SELECT AVG(sal) FROM emp WHERE t.deptno = deptno) ORDER BY deptno;
Overview of Implicit Cursors
Oracle implicitly opens a cursor to process each SQL
statement not associated with an explicitly declared cursor. You can
refer to the most recent implicit cursor as the
SQL cursor. Although you cannot use the OPEN, FETCH, and CLOSE statements to control the SQL cursor, you can use cursor attributes to get information about the most recently executed SQL statement. See "Using Cursor Attributes".Separating Cursor Specs and Bodies with Packages
You can separate a cursor specification (spec for short)
from its body for placement in a package. That way, you can change the
cursor body without having to change the cursor spec. You code the
cursor spec in the package spec using this syntax:
CURSOR cursor_name [(parameter[, parameter]...)] RETURN return_type;
In the following example, you use the
%ROWTYPE attribute to provide a record type that represents a row in the database table emp:CREATE PACKAGE emp_stuff AS CURSOR c1 RETURN emp%ROWTYPE; -- declare cursor spec ... END emp_stuff; CREATE PACKAGE BODY emp_stuff AS CURSOR c1 RETURN emp%ROWTYPE IS SELECT * FROM emp WHERE sal > 2500; -- define cursor body ... END emp_stuff;
The cursor spec has no
SELECT statement because the RETURN clause specifies the datatype of the return value. However, the cursor body must have a SELECT statement and the same RETURN clause as the cursor spec. Also, the number and datatypes of items in the SELECT list and the RETURN clause must match.
Packaged cursors increase flexibility. For instance, you
can change the cursor body in the last example, as follows, without
having to change the cursor spec:
CREATE PACKAGE BODY emp_stuff AS CURSOR c1 RETURN emp%ROWTYPE IS SELECT * FROM emp WHERE deptno = 20; -- new WHERE clause ... END emp_stuff;
From a PL/SQL block or subprogram, you use dot notation to reference a packaged cursor, as the following example shows:
DECLARE emp_rec emp%ROWTYPE; ... BEGIN ... OPEN emp_stuff.c1; LOOP FETCH emp_stuff.c1 INTO emp_rec; EXIT WHEN emp_suff.c1%NOTFOUND; ... END LOOP; CLOSE emp_stuff.c1; END;
The scope of a packaged cursor is not limited to a
particular PL/SQL block. So, when you open a packaged cursor, it remains
open until you close it or you disconnect your Oracle session.
Using Cursor FOR Loops
In most situations that require an explicit cursor, you can simplify coding by using a cursor
FOR loop instead of the OPEN, FETCH, and CLOSE statements. A cursor FOR loop implicitly declares its loop index as a %ROWTYPE
record, opens a cursor, repeatedly fetches rows of values from the
result set into fields in the record, and closes the cursor when all
rows have been processed.
Consider the PL/SQL block below, which computes results from an experiment, then stores the results in a temporary table. The
FOR loop index c1_rec is implicitly declared as a record. Its fields store all the column values fetched from the cursor c1. Dot notation is used to reference individual fields.-- available online in file 'examp7' DECLARE result temp.col1%TYPE; CURSOR c1 IS SELECT n1, n2, n3 FROM data_table WHERE exper_num = 1; BEGIN FOR c1_rec IN c1 LOOP /* calculate and store the results */ result := c1_rec.n2 / (c1_rec.n1 + c1_rec.n3); INSERT INTO temp VALUES (result, NULL, NULL); END LOOP; COMMIT; END;
When the cursor
FOR loop is entered, the cursor name cannot belong to a cursor already opened by an OPEN statement or enclosing cursor FOR loop. Before each iteration of the FOR
loop, PL/SQL fetches into the implicitly declared record. The record is
defined only inside the loop. You cannot refer to its fields outside
the loop.
The sequence of statements inside the loop is executed
once for each row that satisfies the query associated with the cursor.
When you leave the loop, the cursor is closed automatically--even if you
use an
EXIT or GOTO statement to leave the loop prematurely or an exception is raised inside the loop.Using Subqueries Instead of Explicit Cursors
You need not declare a cursor because PL/SQL lets you substitute a subquery. The following cursor
FOR loop calculates a bonus, then inserts the result into a database table:DECLARE bonus REAL; BEGIN FOR emp_rec IN (SELECT empno, sal, comm FROM emp) LOOP bonus := (emp_rec.sal * 0.05) + (emp_rec.comm * 0.25); INSERT INTO bonuses VALUES (emp_rec.empno, bonus); END LOOP; COMMIT; END;
Using Cursor Subqueries
You can use cursor subqueries, also know as cursor
expressions, to pass sets of rows as parameters to functions. For
example, this statement passes a parameter to the StockPivot function
consisting of a REF CURSOR that represents the rows returned by the
cursor subquery:
SELECT * FROM TABLE(StockPivot(CURSOR(SELECT * FROM StockTable)));
Cursor subqueries are often used with table functions, which are explained in "Accepting and Returning Multiple Rows with Table Functions".
Defining Aliases for Expression Values in a Cursor FOR Loop
Fields in the implicitly declared record hold column
values from the most recently fetched row. The fields have the same
names as corresponding columns in the
SELECT list. But, what happens if a select item is an expression? Consider the following example:CURSOR c1 IS SELECT empno, sal+NVL(comm,0), job FROM ...
In such cases, you must include an alias for the select item. In the following example,
wages is an alias for the select item sal+NVL(comm,0):CURSOR c1 IS SELECT empno, sal+NVL(comm,0) wages, job FROM ...
To reference the corresponding field, use the alias instead of a column name, as follows:
IF emp_rec.wages < 1000 THEN ...
Passing Parameters to a Cursor FOR Loop
You can pass parameters to the cursor in a cursor
FOR
loop. In the following example, you pass a department number. Then, you
compute the total wages paid to employees in that department. Also, you
determine how many employees have salaries higher than $2000 and/or
commissions larger than their salaries.-- available online in file 'examp8' DECLARE CURSOR emp_cursor(dnum NUMBER) IS SELECT sal, comm FROM emp WHERE deptno = dnum; total_wages NUMBER(11,2) := 0; high_paid NUMBER(4) := 0; higher_comm NUMBER(4) := 0; BEGIN /* The number of iterations will equal the number of rows returned by emp_cursor. */ FOR emp_record IN emp_cursor(20) LOOP emp_record.comm := NVL(emp_record.comm, 0); total_wages := total_wages + emp_record.sal + emp_record.comm; IF emp_record.sal > 2000.00 THEN high_paid := high_paid + 1; END IF; IF emp_record.comm > emp_record.sal THEN higher_comm := higher_comm + 1; END IF; END LOOP; INSERT INTO temp VALUES (high_paid, higher_comm, 'Total Wages: ' || TO_CHAR(total_wages)); COMMIT; END;
Using Cursor Variables
Like a cursor, a cursor variable points to the current row
in the result set of a multi-row query. But, cursors differ from cursor
variables the way constants differ from variables. Whereas a cursor is
static, a cursor variable is dynamic because it is not tied to a
specific query. You can open a cursor variable for any type-compatible
query. This gives you more flexibility.
Also, you can assign new values to a cursor variable and
pass it as a parameter to local and stored subprograms. This gives you
an easy way to centralize data retrieval.
Cursor variables are available to every PL/SQL client. For
example, you can declare a cursor variable in a PL/SQL host environment
such as an OCI or Pro*C program, then pass it as an input host variable
(bind variable) to PL/SQL. Moreover, application development tools such
as Oracle Forms and Oracle Reports, which have a PL/SQL engine, can use
cursor variables entirely on the client side.
The Oracle server also has a PL/SQL engine. So, you can
pass cursor variables back and forth between an application and server
through remote procedure calls (RPCs).
What Are Cursor Variables?
Cursor variables are like C or Pascal pointers, which hold
the memory location (address) of some item instead of the item itself.
So, declaring a cursor variable creates a pointer, not an item. In PL/SQL, a pointer has datatype
REF X, where REF is short for REFERENCE and X stands for a class of objects. Therefore, a cursor variable has datatype REF CURSOR.
To execute a multi-row query, Oracle opens an unnamed work
area that stores processing information. To access the information, you
can use an explicit cursor, which names the work area. Or, you can use a
cursor variable, which points to the work area. Whereas a cursor always
refers to the same query work area, a cursor variable can refer to
different work areas. So, cursors and cursor variables are not interoperable; that is, you cannot use one where the other is expected.
Why Use Cursor Variables?
Mainly, you use cursor variables to pass query result sets
between PL/SQL stored subprograms and various clients. Neither PL/SQL
nor any of its clients owns a result set; they simply share a pointer to
the query work area in which the result set is stored. For example, an
OCI client, Oracle Forms application, and Oracle server can all refer to
the same work area.
A query work area remains accessible as long as any cursor
variable points to it. Therefore, you can pass the value of a cursor
variable freely from one scope to another. For example, if you pass a
host cursor variable to a PL/SQL block embedded in a Pro*C program, the
work area to which the cursor variable points remains accessible after
the block completes.
If you have a PL/SQL engine on the client side, calls from
client to server impose no restrictions. For example, you can declare a
cursor variable on the client side, open and fetch from it on the
server side, then continue to fetch from it back on the client side.
Also, you can reduce network traffic by having a PL/SQL block open (or
close) several host cursor variables in a single round trip.
Defining REF CURSOR Types
To create cursor variables, you take two steps. First, you define a
REF CURSOR type, then declare cursor variables of that type. You can define REF CURSOR types in any PL/SQL block, subprogram, or package using the syntaxTYPE ref_type_name IS REF CURSOR [RETURN return_type];
where
ref_type_name is a type specifier used in subsequent declarations of cursor variables and return_type
must represent a record or a row in a database table. In the following
example, you specify a return type that represents a row in the database
table dept:DECLARE TYPE DeptCurTyp IS REF CURSOR RETURN dept%ROWTYPE;
REF CURSOR types can be strong (restrictive) or weak (nonrestrictive). As the next example shows, a strong REF CURSOR type definition specifies a return type, but a weak definition does not:DECLARE TYPE EmpCurTyp IS REF CURSOR RETURN emp%ROWTYPE; -- strong TYPE GenericCurTyp IS REF CURSOR; -- weak
Strong
REF CURSOR types are less
error prone because the PL/SQL compiler lets you associate a strongly
typed cursor variable only with type-compatible queries. However, weak REF CURSOR types are more flexible because the compiler lets you associate a weakly typed cursor variable with any query.Declaring Cursor Variables
Once you define a
REF CURSOR
type, you can declare cursor variables of that type in any PL/SQL block
or subprogram. In the following example, you declare the cursor variable
dept_cv:DECLARE TYPE DeptCurTyp IS REF CURSOR RETURN dept%ROWTYPE; dept_cv DeptCurTyp; -- declare cursor variable
Note: You cannot declare
cursor variables in a package. Unlike packaged variables, cursor
variables do not have persistent state. Remember, declaring a cursor
variable creates a pointer, not an item. So, cursor variables cannot be
saved in the database.
Cursor variables follow the usual scoping and
instantiation rules. Local PL/SQL cursor variables are instantiated when
you enter a block or subprogram and cease to exist when you exit.
In the
RETURN clause of a REF CURSOR type definition, you can use %ROWTYPE to specify a record type that represents a row returned by a strongly (not weakly) typed cursor variable, as follows:DECLARE TYPE TmpCurTyp IS REF CURSOR RETURN emp%ROWTYPE; tmp_cv TmpCurTyp; -- declare cursor variable TYPE EmpCurTyp IS REF CURSOR RETURN tmp_cv%ROWTYPE; emp_cv EmpCurTyp; -- declare cursor variable
Likewise, you can use
%TYPE to provide the datatype of a record variable, as the following example shows:DECLARE dept_rec dept%ROWTYPE; -- declare record variable TYPE DeptCurTyp IS REF CURSOR RETURN dept_rec%TYPE; dept_cv DeptCurTyp; -- declare cursor variable
In the final example, you specify a user-defined
RECORD type in the RETURN clause:DECLARE TYPE EmpRecTyp IS RECORD ( empno NUMBER(4), ename VARCHAR2(1O), sal NUMBER(7,2)); TYPE EmpCurTyp IS REF CURSOR RETURN EmpRecTyp; emp_cv EmpCurTyp; -- declare cursor variable
Cursor Variables As Parameters
You can declare cursor variables as the formal parameters of functions and procedures. In the following example, you define the
REF CURSOR type EmpCurTyp, then declare a cursor variable of that type as the formal parameter of a procedure:DECLARE TYPE EmpCurTyp IS REF CURSOR RETURN emp%ROWTYPE; PROCEDURE open_emp_cv (emp_cv IN OUT EmpCurTyp) IS ...
Caution: Like all pointers, cursor variables increase the possibility of parameter aliasing. See "Understanding Subprogram Parameter Aliasing".
Controlling Cursor Variables
You use three statements to control a cursor variable:
OPEN-FOR, FETCH, and CLOSE. First, you OPEN a cursor variable FOR a multi-row query. Then, you FETCH rows from the result set. When all the rows are processed, you CLOSE the cursor variable.Opening a Cursor Variable
The
OPEN-FOR statement associates a cursor
variable with a multi-row query, executes the query, and identifies the
result set. Here is the syntax:OPEN {cursor_variable | :host_cursor_variable} FOR { select_statement | dynamic_string [USING bind_argument[, bind_argument]...] };
where
host_cursor_variable is a cursor variable declared in a PL/SQL host environment such as an OCI program, and dynamic_string is a string expression that represents a multi-row query.
Note: This section discusses the static SQL case, in which
select_statement is used. For the dynamic SQL case, in which dynamic_string is used, see "Opening the Cursor Variable".
Unlike cursors, cursor variables take no parameters.
However, no flexibility is lost because you can pass whole queries (not
just parameters) to a cursor variable. The query can reference host
variables and PL/SQL variables, parameters, and functions.
In the example below, you open the cursor variable
emp_cv. Notice that you can apply cursor attributes (%FOUND, %NOTFOUND, %ISOPEN, and %ROWCOUNT) to a cursor variable.IF NOT emp_cv%ISOPEN THEN /* Open cursor variable. */ OPEN emp_cv FOR SELECT * FROM emp; END IF;
Other
OPEN-FOR statements can open the same
cursor variable for different queries. You need not close a cursor
variable before reopening it. (Recall that consecutive OPENs of a static cursor raise the predefined exception CURSOR_ALREADY_OPEN.) When you reopen a cursor variable for a different query, the previous query is lost.
Typically, you open a cursor variable by passing it to a
stored procedure that declares a cursor variable as one of its formal
parameters. For example, the following packaged procedure opens the
cursor variable
emp_cv:CREATE PACKAGE emp_data AS ... TYPE EmpCurTyp IS REF CURSOR RETURN emp%ROWTYPE; PROCEDURE open_emp_cv (emp_cv IN OUT EmpCurTyp); END emp_data; CREATE PACKAGE BODY emp_data AS ... PROCEDURE open_emp_cv (emp_cv IN OUT EmpCurTyp) IS BEGIN OPEN emp_cv FOR SELECT * FROM emp; END open_emp_cv; END emp_data;
When you declare a cursor variable as the formal parameter of a subprogram that opens the cursor variable, you must specify the
IN OUT mode. That way, the subprogram can pass an open cursor back to the caller.
Alternatively, you can use a standalone procedure to open the cursor variable. Simply define the
REF CURSOR
type in a separate package, then reference that type in the standalone
procedure. For instance, if you create the following bodiless package,
you can create standalone procedures that reference the types it
defines:CREATE PACKAGE cv_types AS TYPE GenericCurTyp IS REF CURSOR; TYPE EmpCurTyp IS REF CURSOR RETURN emp%ROWTYPE; TYPE DeptCurTyp IS REF CURSOR RETURN dept%ROWTYPE; ... END cv_types;
In the next example, you create a standalone procedure that references the
REF CURSOR type EmpCurTyp, which is defined in the package cv_types:CREATE PROCEDURE open_emp_cv (emp_cv IN OUT cv_types.EmpCurTyp) AS BEGIN OPEN emp_cv FOR SELECT * FROM emp; END open_emp_cv;
To centralize data retrieval, you can group
type-compatible queries in a stored procedure. In the example below, the
packaged procedure declares a selector as one of its formal parameters.
When called, the procedure opens the cursor variable
emp_cv for the chosen query.CREATE PACKAGE emp_data AS TYPE EmpCurTyp IS REF CURSOR RETURN emp%ROWTYPE; PROCEDURE open_emp_cv (emp_cv IN OUT EmpCurTyp, choice INT); END emp_data; CREATE PACKAGE BODY emp_data AS PROCEDURE open_emp_cv (emp_cv IN OUT EmpCurTyp, choice INT) IS BEGIN IF choice = 1 THEN OPEN emp_cv FOR SELECT * FROM emp WHERE comm IS NOT NULL; ELSIF choice = 2 THEN OPEN emp_cv FOR SELECT * FROM emp WHERE sal > 2500; ELSIF choice = 3 THEN OPEN emp_cv FOR SELECT * FROM emp WHERE deptno = 20; END IF; END; END emp_data;
For more flexibility, you can pass a cursor variable and a
selector to a stored procedure that executes queries with different
return types. Here is an example:
CREATE PACKAGE admin_data AS TYPE GenCurTyp IS REF CURSOR; PROCEDURE open_cv (generic_cv IN OUT GenCurTyp, choice INT); END admin_data; CREATE PACKAGE BODY admin_data AS PROCEDURE open_cv (generic_cv IN OUT GenCurTyp, choice INT) IS BEGIN IF choice = 1 THEN OPEN generic_cv FOR SELECT * FROM emp; ELSIF choice = 2 THEN OPEN generic_cv FOR SELECT * FROM dept; ELSIF choice = 3 THEN OPEN generic_cv FOR SELECT * FROM salgrade; END IF; END; END admin_data;
Using a Cursor Variable as a Host Variable
You can declare a cursor variable in a PL/SQL host
environment such as an OCI or Pro*C program. To use the cursor variable,
you must pass it as a host variable to PL/SQL. In the following Pro*C
example, you pass a host cursor variable and selector to a PL/SQL block,
which opens the cursor variable for the chosen query:
EXEC SQL BEGIN DECLARE SECTION; ... /* Declare host cursor variable. */ SQL_CURSOR generic_cv; int choice; EXEC SQL END DECLARE SECTION; ... /* Initialize host cursor variable. */ EXEC SQL ALLOCATE :generic_cv; ... /* Pass host cursor variable and selector to PL/SQL block. */ EXEC SQL EXECUTE BEGIN IF :choice = 1 THEN OPEN :generic_cv FOR SELECT * FROM emp; ELSIF :choice = 2 THEN OPEN :generic_cv FOR SELECT * FROM dept; ELSIF :choice = 3 THEN OPEN :generic_cv FOR SELECT * FROM salgrade; END IF; END; END-EXEC;
Host cursor variables are compatible with any query return type. They behave just like weakly typed PL/SQL cursor variables.
Fetching from a Cursor Variable
The
FETCH statement retrieves rows from the result set of a multi-row query. Here is the syntax:FETCH {cursor_variable_name | :host_cursor_variable_name} [BULK COLLECT] INTO {variable_name[, variable_name]... | record_name};
In the following example, you fetch rows one at a time from the cursor variable
emp_cv into the user-defined record emp_rec:LOOP /* Fetch from cursor variable. */ FETCH emp_cv INTO emp_rec; EXIT WHEN emp_cv%NOTFOUND; -- exit when last row is fetched -- process data record END LOOP;
Using the
BULK COLLECT clause, you can bulk fetch rows from a cursor variable into one or more collections. An example follows:DECLARE TYPE EmpCurTyp IS REF CURSOR RETURN emp%ROWTYPE; TYPE NameList IS TABLE OF emp.ename%TYPE; TYPE SalList IS TABLE OF emp.sal%TYPE; emp_cv EmpCurTyp; names NameList; sals SalList; BEGIN OPEN emp_cv FOR SELECT ename, sal FROM emp; FETCH emp_cv BULK COLLECT INTO names, sals; ... END;
Any variables in the associated query are evaluated only
when the cursor variable is opened. To change the result set or the
values of variables in the query, you must reopen the cursor variable
with the variables set to their new values. However, you can use a
different
INTO clause on separate fetches with the same cursor variable. Each fetch retrieves another row from the same result set.
PL/SQL makes sure the return type of the cursor variable is compatible with the
INTO clause of the FETCH
statement. For each column value returned by the query associated with
the cursor variable, there must be a corresponding, type-compatible
field or variable in the INTO clause. Also, the number of
fields or variables must equal the number of column values. Otherwise,
you get an error. The error occurs at compile time if the cursor
variable is strongly typed or at run time if it is weakly typed. At run
time, PL/SQL raises the predefined exception ROWTYPE_MISMATCH before the first fetch. So, if you trap the error and execute the FETCH statement using a different INTO clause, no rows are lost.
When you declare a cursor variable as the formal parameter
of a subprogram that fetches from the cursor variable, you must specify
the
IN or IN OUT mode. However, if the subprogram also opens the cursor variable, you must specify the IN OUT mode.
If you try to fetch from a closed or never-opened cursor variable, PL/SQL raises the predefined exception
INVALID_CURSOR.Closing a Cursor Variable
The
CLOSE statement disables a cursor variable. After that, the associated result set is undefined. Here is the syntax:CLOSE {cursor_variable_name | :host_cursor_variable_name);
In the following example, when the last row is processed, you close the cursor variable
emp_cv:LOOP FETCH emp_cv INTO emp_rec; EXIT WHEN emp_cv%NOTFOUND; -- process data record END LOOP; /* Close cursor variable. */ CLOSE emp_cv;
When declaring a cursor variable as the formal parameter of a subprogram that closes the cursor variable, you must specify the
IN or IN OUT mode.
If you try to close an already-closed or never-opened cursor variable, PL/SQL raises the predefined exception
INVALID_CURSOR.Cursor Variable Example: Master Table and Details Tables
Consider the stored procedure below, which searches the
database of a main library for books, periodicals, and tapes. A master
table stores the title and category code (where
1 = book, 2 = periodical, 3
= tape) of each item. Three detail tables store category-specific
information. When called, the procedure searches the master table by
title, uses the associated category code to pick an OPEN-FOR statement, then opens a cursor variable for a query of the proper detail table.CREATE PACKAGE cv_types AS TYPE LibCurTyp IS REF CURSOR; ... END cv_types; CREATE PROCEDURE find_item ( title VARCHAR2(100), lib_cv IN OUT cv_types.LibCurTyp) AS code BINARY_INTEGER; BEGIN SELECT item_code FROM titles INTO code WHERE item_title = title; IF code = 1 THEN OPEN lib_cv FOR SELECT * FROM books WHERE book_title = title; ELSIF code = 2 THEN OPEN lib_cv FOR SELECT * FROM periodicals WHERE periodical_title = title; ELSIF code = 3 THEN OPEN lib_cv FOR SELECT * FROM tapes WHERE tape_title = title; END IF; END find_item;
Cursor Variable Example: Client-Side PL/SQL Block
A client-side application in a branch library might use the following PL/SQL block to display the retrieved information:
DECLARE lib_cv cv_types.LibCurTyp; book_rec books%ROWTYPE; periodical_rec periodicals%ROWTYPE; tape_rec tapes%ROWTYPE; BEGIN get_title(:title); -- title is a host variable find_item(:title, lib_cv); FETCH lib_cv INTO book_rec; display_book(book_rec); EXCEPTION WHEN ROWTYPE_MISMATCH THEN BEGIN FETCH lib_cv INTO periodical_rec; display_periodical(periodical_rec); EXCEPTION WHEN ROWTYPE_MISMATCH THEN FETCH lib_cv INTO tape_rec; display_tape(tape_rec); END; END;
Cursor Variable Example: Pro*C Program
The following Pro*C program prompts the user to select a
database table, opens a cursor variable for a query of that table, then
fetches rows returned by the query:
#include <stdio.h> #include <sqlca.h> void sql_error(); main() { char temp[32]; EXEC SQL BEGIN DECLARE SECTION; char * uid = "scott/tiger"; SQL_CURSOR generic_cv; /* cursor variable */ int table_num; /* selector */ struct /* EMP record */ { int emp_num; char emp_name[11]; char job_title[10]; int manager; char hire_date[10]; float salary; float commission; int dept_num; } emp_rec; struct /* DEPT record */ { int dept_num; char dept_name[15]; char location[14]; } dept_rec; struct /* BONUS record */ { char emp_name[11]; char job_title[10]; float salary; } bonus_rec; EXEC SQL END DECLARE SECTION; /* Handle Oracle errors. */ EXEC SQL WHENEVER SQLERROR DO sql_error(); /* Connect to Oracle. */ EXEC SQL CONNECT :uid; /* Initialize cursor variable. */ EXEC SQL ALLOCATE :generic_cv; /* Exit loop when done fetching. */ EXEC SQL WHENEVER NOT FOUND DO break; for (;;) { printf("\n1 = EMP, 2 = DEPT, 3 = BONUS"); printf("\nEnter table number (0 to quit): "); gets(temp); table_num = atoi(temp); if (table_num <= 0) break; /* Open cursor variable. */ EXEC SQL EXECUTE BEGIN IF :table_num = 1 THEN OPEN :generic_cv FOR SELECT * FROM emp; ELSIF :table_num = 2 THEN OPEN :generic_cv FOR SELECT * FROM dept; ELSIF :table_num = 3 THEN OPEN :generic_cv FOR SELECT * FROM bonus; END IF; END; END-EXEC; for (;;) { switch (table_num) { case 1: /* Fetch row into EMP record. */ EXEC SQL FETCH :generic_cv INTO :emp_rec; break; case 2: /* Fetch row into DEPT record. */ EXEC SQL FETCH :generic_cv INTO :dept_rec; break; case 3: /* Fetch row into BONUS record. */ EXEC SQL FETCH :generic_cv INTO :bonus_rec; break; } /* Process data record here. */ } /* Close cursor variable. */ EXEC SQL CLOSE :generic_cv; } exit(0); } void sql_error() { /* Handle SQL error here. */ }
Cursor Variable Example: Manipulating Host Variables in SQL*Plus
A host variable is a variable you declare in a host
environment, then pass to one or more PL/SQL programs, which can use it
like any other variable. In the SQL*Plus environment, to declare a host
variable, use the command
VARIABLE. For example, you declare a variable of type NUMBER as follows:VARIABLE return_code NUMBER
Both SQL*Plus and PL/SQL can reference the host variable,
and SQL*Plus can display its value. However, to reference a host
variable in PL/SQL, you must prefix its name with a colon (
:), as the following example shows:DECLARE ... BEGIN :return_code := 0; IF credit_check_ok(acct_no) THEN :return_code := 1; END IF; ... END;
To display the value of a host variable in SQL*Plus, use the
PRINT command, as follows:SQL> PRINT return_code RETURN_CODE ----------- 1
The SQL*Plus datatype
REFCURSOR lets you
declare cursor variables, which you can use to return query results from
stored subprograms. In the script below, you declare a host variable of
type REFCURSOR. You use the SQL*Plus command SET AUTOPRINT ON to display the query results automatically.CREATE PACKAGE emp_data AS TYPE EmpRecTyp IS RECORD ( emp_id NUMBER(4), emp_name VARCHAR2(10), job_title VARCHAR2(9), dept_name VARCHAR2(14), dept_loc VARCHAR2(13)); TYPE EmpCurTyp IS REF CURSOR RETURN EmpRecTyp; PROCEDURE get_staff ( dept_no IN NUMBER, emp_cv IN OUT EmpCurTyp); END; / CREATE PACKAGE BODY emp_data AS PROCEDURE get_staff ( dept_no IN NUMBER, emp_cv IN OUT EmpCurTyp) IS BEGIN OPEN emp_cv FOR SELECT empno, ename, job, dname, loc FROM emp, dept WHERE emp.deptno = dept_no AND emp.deptno = dept.deptno ORDER BY empno; END; END; / COLUMN EMPNO HEADING Number COLUMN ENAME HEADING Name COLUMN JOB HEADING JobTitle COLUMN DNAME HEADING Department COLUMN LOC HEADING Location SET AUTOPRINT ON VARIABLE cv REFCURSOR EXECUTE emp_data.get_staff(20, :cv)
Reducing Network Traffic When Passing Host Cursor Variables to PL/SQL
When passing host cursor variables to PL/SQL, you can reduce network traffic by grouping
OPEN-FOR statements. For example, the following PL/SQL block opens five cursor variables in a single round trip:/* anonymous PL/SQL block in host environment */ BEGIN OPEN :emp_cv FOR SELECT * FROM emp; OPEN :dept_cv FOR SELECT * FROM dept; OPEN :grade_cv FOR SELECT * FROM salgrade; OPEN :pay_cv FOR SELECT * FROM payroll; OPEN :ins_cv FOR SELECT * FROM insurance; END;
This might be useful in Oracle Forms, for instance, when you want to populate a multi-block form.
When you pass host cursor variables to a PL/SQL block for
opening, the query work areas to which they point remain accessible
after the block completes. That allows your OCI or Pro*C program to use
these work areas for ordinary cursor operations. In the following
example, you open several such work areas in a single round trip:
BEGIN OPEN :c1 FOR SELECT 1 FROM dual; OPEN :c2 FOR SELECT 1 FROM dual; OPEN :c3 FOR SELECT 1 FROM dual; OPEN :c4 FOR SELECT 1 FROM dual; OPEN :c5 FOR SELECT 1 FROM dual; ... END;
The cursors assigned to
c1, c2, c3, c4, and c5 behave normally, and you can use them for any purpose. When finished, simply release the cursors, as follows:BEGIN CLOSE :c1; CLOSE :c2; CLOSE :c3; CLOSE :c4; CLOSE :c5; ... END;
Avoiding Errors with Cursor Variables
If both cursor variables involved in an assignment are
strongly typed, they must have the same datatype. In the following
example, even though the cursor variables have the same return type, the
assignment raises an exception because they have different datatypes:
DECLARE TYPE EmpCurTyp IS REF CURSOR RETURN emp%ROWTYPE; TYPE TmpCurTyp IS REF CURSOR RETURN emp%ROWTYPE; PROCEDURE open_emp_cv ( emp_cv IN OUT EmpCurTyp, tmp_cv IN OUT TmpCurTyp) IS BEGIN ... emp_cv := tmp_cv; -- causes 'wrong type' error END;
However, if one or both cursor variables are weakly typed, they need not have the same datatype.
If you try to fetch from, close, or apply cursor
attributes to a cursor variable that does not point to a query work
area, PL/SQL raises
INVALID_CURSOR. You can make a cursor variable (or parameter) point to a query work area in two ways:OPENthe cursor variableFORthe query.- Assign to the cursor variable the value of an already
OPENed host cursor variable or PL/SQL cursor variable.
The following example shows how these ways interact:
DECLARE TYPE EmpCurTyp IS REF CURSOR RETURN emp%ROWTYPE; emp_cv1 EmpCurTyp; emp_cv2 EmpCurTyp; emp_rec emp%ROWTYPE; BEGIN /* The following assignment is useless because emp_cv1 does not point to a query work area yet. */ emp_cv2 := emp_cv1; -- useless /* Make emp_cv1 point to a query work area. */ OPEN emp_cv1 FOR SELECT * FROM emp; /* Use emp_cv1 to fetch first row from emp table. */ FETCH emp_cv1 INTO emp_rec; /* The following fetch raises an exception because emp_cv2 does not point to a query work area yet. */ FETCH emp_cv2 INTO emp_rec; -- raises INVALID_CURSOR EXCEPTION WHEN INVALID_CURSOR THEN /* Make emp_cv1 and emp_cv2 point to same work area. */ emp_cv2 := emp_cv1; /* Use emp_cv2 to fetch second row from emp table. */ FETCH emp_cv2 INTO emp_rec; /* Reuse work area for another query. */ OPEN emp_cv2 FOR SELECT * FROM old_emp; /* Use emp_cv1 to fetch first row from old_emp table. The following fetch succeeds because emp_cv1 and emp_cv2 point to the same query work area. */ FETCH emp_cv1 INTO emp_rec; -- succeeds END;
Be careful when passing cursor variables as parameters. At run time, PL/SQL raises
ROWTYPE_MISMATCH if the return types of the actual and formal parameters are incompatible.
In the Pro*C example below, you define a packaged
REF CURSOR type, specifying the return type emp%ROWTYPE.
Next, you create a standalone procedure that references the new type.
Then, inside a PL/SQL block, you open a host cursor variable for a query
of the dept table. Later, when you pass the open host cursor variable to the stored procedure, PL/SQL raises ROWTYPE_MISMATCH because the return types of the actual and formal parameters are incompatible.CREATE PACKAGE cv_types AS TYPE EmpCurTyp IS REF CURSOR RETURN emp%ROWTYPE; ... END cv_types; / CREATE PROCEDURE open_emp_cv (emp_cv IN OUT cv_types.EmpCurTyp) AS BEGIN OPEN emp_cv FOR SELECT * FROM emp; END open_emp_cv; / -- anonymous PL/SQL block in Pro*C program EXEC SQL EXECUTE BEGIN OPEN :cv FOR SELECT * FROM dept; ... open_emp_cv(:cv); -- raises ROWTYPE_MISMATCH END; END-EXEC;
Restrictions on Cursor Variables
Currently, cursor variables are subject to the following restrictions:
- You cannot declare cursor variables in a package. For example, the following declaration is not allowed:
CREATE PACKAGE emp_stuff AS TYPE EmpCurTyp IS REF CURSOR RETURN emp%ROWTYPE; emp_cv EmpCurTyp; -- not allowed END emp_stuff;
- Remote subprograms on another server cannot accept the values of cursor variables. Therefore, you cannot use RPCs to pass cursor variables from one server to another.
- If you pass a host cursor variable to PL/SQL, you cannot fetch from it on the server side unless you also open it there on the same server call.
- You cannot use comparison operators to test cursor variables for equality, inequality, or nullity.
- You cannot assign nulls to a cursor variable.
- You cannot use
REFCURSORtypes to specify column types in aCREATETABLEorCREATEVIEWstatement. So, database columns cannot store the values of cursor variables. - You cannot use a
REFCURSORtype to specify the element type of a collection, which means that elements in a index-by table, nested table, or varray cannot store the values of cursor variables. - Cursors and cursor
variables are not interoperable; that is, you cannot use one where the
other is expected. For example, the following cursor
FORloop is not allowed because it attempts to fetch from a cursor variable:DECLARE TYPE EmpCurTyp IS REF CURSOR RETURN emp%ROWTYPE; emp_cv EmpCurTyp; ... BEGIN ... FOR emp_rec IN emp_cv LOOP ... -- not allowed END;
Using Cursor Attributes
Every explicit cursor and cursor variable has four attributes:
%FOUND, %ISOPEN %NOTFOUND, and %ROWCOUNT.
When appended to the cursor or cursor variable, these attributes return
useful information about the execution of a data manipulation
statement. You can use cursor attributes in procedural statements but
not in SQL statements.Overview of Explicit Cursor Attributes
Explicit cursor attributes return information about the
execution of a multi-row query. When an explicit cursor or a cursor
variable is opened, the rows that satisfy the associated query are
identified and form the result set. Rows are fetched from the result
set.
%FOUND Attribute: Has a Row Been Fetched?
After a cursor or cursor variable is opened but before the first fetch,
%FOUND yields NULL. Thereafter, it yields TRUE if the last fetch returned a row, or FALSE if the last fetch failed to return a row. In the following example, you use %FOUND to select an action:LOOP FETCH c1 INTO my_ename, my_sal, my_hiredate; IF c1%FOUND THEN -- fetch succeeded ... ELSE -- fetch failed, so exit loop EXIT; END IF; END LOOP;
If a cursor or cursor variable is not open, referencing it with
%FOUND raises the predefined exception INVALID_CURSOR.%ISOPEN Attribute: Is the Cursor Open?
%ISOPEN yields TRUE if its cursor or cursor variable is open; otherwise, %ISOPEN yields FALSE. In the following example, you use %ISOPEN to select an action:IF c1%ISOPEN THEN -- cursor is open ... ELSE -- cursor is closed, so open it OPEN c1; END IF;
%NOTFOUND Attribute: Has a Fetch Failed?
%NOTFOUND is the logical opposite of %FOUND. %NOTFOUND yields FALSE if the last fetch returned a row, or TRUE if the last fetch failed to return a row. In the following example, you use %NOTFOUND to exit a loop when FETCH fails to return a row:LOOP FETCH c1 INTO my_ename, my_sal, my_hiredate; EXIT WHEN c1%NOTFOUND; ... END LOOP;
Before the first fetch,
%NOTFOUND evaluates to NULL. So, if FETCH never executes successfully, the loop is never exited. That is because the EXIT WHEN statement executes only if its WHEN condition is true. To be safe, you might want to use the following EXIT statement instead:EXIT WHEN c1%NOTFOUND OR c1%NOTFOUND IS NULL;
If a cursor or cursor variable is not open, referencing it with
%NOTFOUND raises INVALID_CURSOR.%ROWCOUNT Attribute: How Many Rows Fetched So Far?
When its cursor or cursor variable is opened,
%ROWCOUNT is zeroed. Before the first fetch, %ROWCOUNT yields 0.
Thereafter, it yields the number of rows fetched so far. The number is
incremented if the last fetch returned a row. In the next example, you
use %ROWCOUNT to take action if more than ten rows have been fetched:LOOP FETCH c1 INTO my_ename, my_deptno; IF c1%ROWCOUNT > 10 THEN ... END IF; ... END LOOP;
If a cursor or cursor variable is not open, referencing it with
%ROWCOUNT raises INVALID_CURSOR.
Table 6-1 shows what each cursor attribute yields before and after you execute an
OPEN, FETCH, or CLOSE statement.Table 6-1 Cursor Attribute Values
Some Examples of Cursor Attributes
Suppose you have a table named
data_table
that holds data collected from laboratory experiments, and you want to
analyze the data from experiment 1. In the following example, you
compute the results and store them in a database table named temp:-- available online in file 'examp5' DECLARE num1 data_table.n1%TYPE; -- Declare variables num2 data_table.n2%TYPE; -- having same types as num3 data_table.n3%TYPE; -- database columns result temp.col1%TYPE; CURSOR c1 IS SELECT n1, n2, n3 FROM data_table WHERE exper_num = 1; BEGIN OPEN c1; LOOP FETCH c1 INTO num1, num2, num3; EXIT WHEN c1%NOTFOUND; -- TRUE when FETCH finds no more rows result := num2/(num1 + num3); INSERT INTO temp VALUES (result, NULL, NULL); END LOOP; CLOSE c1; COMMIT; END;
In the next example, you check all storage bins that contain part number
5469, withdrawing their contents until you accumulate 1000 units:-- available online in file 'examp6' DECLARE CURSOR bin_cur(part_number NUMBER) IS SELECT amt_in_bin FROM bins WHERE part_num = part_number AND amt_in_bin > 0 ORDER BY bin_num FOR UPDATE OF amt_in_bin; bin_amt bins.amt_in_bin%TYPE; total_so_far NUMBER(5) := 0; amount_needed CONSTANT NUMBER(5) := 1000; bins_looked_at NUMBER(3) := 0; BEGIN OPEN bin_cur(5469); WHILE total_so_far < amount_needed LOOP FETCH bin_cur INTO bin_amt; EXIT WHEN bin_cur%NOTFOUND; -- if we exit, there's not enough to fill the order bins_looked_at := bins_looked_at + 1; IF total_so_far + bin_amt < amount_needed THEN UPDATE bins SET amt_in_bin = 0 WHERE CURRENT OF bin_cur; -- take everything in the bin total_so_far := total_so_far + bin_amt; ELSE -- we finally have enough UPDATE bins SET amt_in_bin = amt_in_bin - (amount_needed - total_so_far) WHERE CURRENT OF bin_cur; total_so_far := amount_needed; END IF; END LOOP; CLOSE bin_cur; INSERT INTO temp VALUES (NULL, bins_looked_at, '<- bins looked at'); COMMIT; END;
Overview of Implicit Cursor Attributes
Implicit cursor attributes return information about the execution of an
INSERT, UPDATE, DELETE, or SELECT INTO
statement. The values of the cursor attributes always refer to the most
recently executed SQL statement. Before Oracle opens the SQL cursor, the implicit cursor attributes yield NULL.
Note: The
SQL cursor has another attribute, %BULK_ROWCOUNT, designed for use with the FORALL statement. For more information, see "Counting Rows Affected by FORALL Iterations with the %BULK_ROWCOUNT Attribute".%FOUND Attribute: Has a DML Statement Changed Rows?
Until a SQL data manipulation statement is executed,
%FOUND yields NULL. Thereafter, %FOUND yields TRUE if an INSERT, UPDATE, or DELETE statement affected one or more rows, or a SELECT INTO statement returned one or more rows. Otherwise, %FOUND yields FALSE. In the following example, you use %FOUND to insert a row if a delete succeeds:DELETE FROM emp WHERE empno = my_empno; IF SQL%FOUND THEN -- delete succeeded INSERT INTO new_emp VALUES (my_empno, my_ename, ...);
%ISOPEN Attribute: Always FALSE for Implicit Cursors
Oracle closes the
SQL cursor automatically after executing its associated SQL statement. As a result, %ISOPEN always yields FALSE.%NOTFOUND Attribute: Has a DML Statement Failed to Change Rows?
%NOTFOUND is the logical opposite of %FOUND. %NOTFOUND yields TRUE if an INSERT, UPDATE, or DELETE statement affected no rows, or a SELECT INTO statement returned no rows. Otherwise, %NOTFOUND yields FALSE.%ROWCOUNT Attribute: How Many Rows Affected So Far?
%ROWCOUNT yields the number of rows affected by an INSERT, UPDATE, or DELETE statement, or returned by a SELECT INTO statement. %ROWCOUNT yields 0 if an INSERT, UPDATE, or DELETE statement affected no rows, or a SELECT INTO statement returned no rows. In the following example, you use %ROWCOUNT to take action if more than ten rows have been deleted:DELETE FROM emp WHERE ... IF SQL%ROWCOUNT > 10 THEN -- more than 10 rows were deleted ... END IF;
If a
SELECT INTO statement returns more than one row, PL/SQL raises the predefined exception TOO_MANY_ROWS and %ROWCOUNT yields 1, not the actual number of rows that satisfy the query.Guidelines for Using Implicit Cursor Attributes
The values of the cursor attributes always refer to the
most recently executed SQL statement, wherever that statement is. It
might be in a different scope (for example, in a sub-block). So, if you
want to save an attribute value for later use, assign it to a Boolean
variable immediately. In the following example, relying on the
IF condition is dangerous because the procedure check_status might have changed the value of %NOTFOUND:BEGIN ... UPDATE parts SET quantity = quantity - 1 WHERE partno = part_id; check_status(part_id); -- procedure call IF SQL%NOTFOUND THEN -- dangerous! ... END; END;
You can improve the code as follows:
BEGIN ... UPDATE parts SET quantity = quantity - 1 WHERE partno = part_id; sql_notfound := SQL%NOTFOUND; -- assign value to Boolean variable check_status(part_id); IF sql_notfound THEN ... END;
If a
SELECT INTO statement fails to return a row, PL/SQL raises the predefined exception NO_DATA_FOUND whether you check %NOTFOUND on the next line or not. Consider the following example:BEGIN ... SELECT sal INTO my_sal FROM emp WHERE empno = my_empno; -- might raise NO_DATA_FOUND IF SQL%NOTFOUND THEN -- condition tested only when false ... -- this action is never taken END IF;
The check is useless because the
IF condition is tested only when %NOTFOUND is false. When PL/SQL raises NO_DATA_FOUND, normal execution stops and control transfers to the exception-handling part of the block.
However, a
SELECT INTO statement that calls a SQL aggregate function never raises NO_DATA_FOUND because aggregate functions always return a value or a null. In such cases, %NOTFOUND yields FALSE, as the following example shows:BEGIN ... SELECT MAX(sal) INTO my_sal FROM emp WHERE deptno = my_deptno; -- never raises NO_DATA_FOUND IF SQL%NOTFOUND THEN -- always tested but never true ... -- this action is never taken END IF; EXCEPTION WHEN NO_DATA_FOUND THEN ... -- never invoked
Using Cursor Expressions
A cursor expression returns a nested cursor. Each row in
the result set can contain values as usual, plus cursors produced by
subqueries involving the other values in the row. Thus, a single query
can return a large set of related values retrieved from multiple tables.
You can process the result set with nested loops that fetch first from
the rows of the result set, then any nested cursors within those rows.
PL/SQL supports queries with cursor expressions as part of cursor declarations,
REF CURSOR declarations and ref cursor variables. You can also use cursor expressions in dynamic SQL queries. Here is the syntax:CURSOR ( subquery )
A nested cursor is implicitly opened when the containing
row is fetched from the parent cursor. The nested cursor is closed only
when:
- The nested cursor is explicitly closed by the user
- The parent cursor is reexecuted
- The parent cursor is closed
- The parent cursor is canceled
- An error arises during a fetch on one of its parent cursors. The nested cursor is closed as part of the clean-up.
Restrictions on Cursor Expressions
- You cannot use a cursor expression with an implicit cursor.
- Cursor expressions can appear only:
- Cursor expressions can appear only in the outermost
SELECTlist of the query specification. - Cursor expressions cannot appear in view declarations.
- You cannot perform
BINDandEXECUTEoperations on cursor expressions.
Example of Cursor Expressions
In this example, we find a specified location ID, and a
cursor from which we can fetch all the departments in that location. As
we fetch each department's name, we also get another cursor that lets us
fetch their associated employee details from another table.
CREATE OR REPLACE procedure emp_report(p_locid number) is TYPE refcursor is ref cursor; -- The query returns only 2 columns, but the second column is -- a cursor that lets us traverse a set of related information. CURSOR c1 is SELECT l.city, CURSOR(SELECT d.department_name, CURSOR(SELECT e.last_name FROM employees e WHERE e.department_id = d.department_id) as ename FROM departments d where l.location_id = d.location_id) dname FROM locations l WHERE l.location_id = p_locid; loccur refcursor; deptcur refcursor; empcur refcursor; V_city locations.city%type; V_dname departments.department_name%type; V_ename employees.last_name%type; BEGIN OPEN c1; LOOP FETCH C1 INTO v_city, loccur; EXIT WHEN c1%notfound; -- We can access the column C1.city, then process the results of -- the nested cursor. LOOP FETCH loccur INTO v_dname, deptcur; -- No need to open EXIT WHEN loccur%notfound; LOOP FETCH deptcur into v_ename; -- No need to open EXIT WHEN deptcur%notfound; DBMS_OUTPUT.PUT_LINE(v_city ||' '||v_dname||' '||v_ename); END LOOP; END LOOP; END LOOP; close c1; END; /
Overview of Transaction Processing in PL/SQL
This section explains how to do transaction processing.
You learn the basic techniques that safeguard the consistency of your
database, including how to control whether changes to Oracle data are
made permanent or undone.
The jobs or tasks that Oracle manages are called sessions. A user session
is started when you run an application program or an Oracle tool and
connect to Oracle. To allow user sessions to work "simultaneously" and
share computer resources, Oracle must control concurrency, the accessing of the same data by many users. Without adequate concurrency controls, there might be a loss of data integrity. That is, changes to data might be made in the wrong order.
Oracle uses locks to control
concurrent access to data. A lock gives you temporary ownership of a
database resource such as a table or row of data. Thus, data cannot be
changed by other users until you finish with it. You need never
explicitly lock a resource because default locking mechanisms protect
Oracle data and structures. However, you can request data locks on tables or rows when it is to your advantage to override default locking. You can choose from several modes of locking such as row share and exclusive.
A deadlock can occur when two or
more users try to access the same schema object. For example, two users
updating the same table might wait if each tries to update a row
currently locked by the other. Because each user is waiting for
resources held by another user, neither can continue until Oracle breaks
the deadlock by signaling an error to the last participating
transaction.
When a table is being queried by one user and updated by another at the same time, Oracle generates a read-consistent
view of the data for the query. That is, once a query begins and as it
proceeds, the data read by the query does not change. As update activity
continues, Oracle takes snapshots of the table's data and records changes in a rollback segment. Oracle uses rollback segments to build read-consistent query results and to undo changes if necessary.
How Transactions Guard Your Database
A transaction is a series of SQL data manipulation
statements that does a logical unit of work. Oracle treats the series of
SQL statements as a unit so that all the changes brought about by the
statements are either committed (made permanent) or rolled back
(undone) at the same time. If your program fails in the middle of a
transaction, the database is automatically restored to its former state.
The first SQL statement in your program begins a
transaction. When one transaction ends, the next SQL statement
automatically begins another transaction. Thus, every SQL statement is
part of a transaction. A distributed transaction includes at least one SQL statement that updates data at multiple nodes in a distributed database.
The
COMMIT and ROLLBACK
statements ensure that all database changes brought about by SQL
operations are either made permanent or undone at the same time. All the
SQL statements executed since the last commit or rollback make up the
current transaction. The SAVEPOINT statement names and marks the current point in the processing of a transaction.Making Changes Permanent with COMMIT
The
COMMIT statement ends the current
transaction and makes permanent any changes made during that
transaction. Until you commit the changes, other users cannot access the
changed data; they see the data as it was before you made the changes.
Consider a simple transaction that transfers money from
one bank account to another. The transaction requires two updates
because it debits the first account, then credits the second. In the
example below, after crediting the second account, you issue a commit,
which makes the changes permanent. Only then do other users see the
changes.
BEGIN ... UPDATE accts SET bal = my_bal - debit WHERE acctno = 7715; ... UPDATE accts SET bal = my_bal + credit WHERE acctno = 7720; COMMIT WORK; END;
The
COMMIT statement releases all row and
table locks. It also erases any savepoints (discussed later) marked
since the last commit or rollback. The optional keyword WORK has no effect other than to improve readability. The keyword END signals the end of a PL/SQL block, not the end of a transaction. Just as a block can span multiple transactions, a transaction can span multiple blocks.
The optional
COMMENT clause lets you specify a
comment to be associated with a distributed transaction. When you issue
a commit, changes to each database affected by a distributed
transaction are made permanent. However, if a network or machine fails
during the commit, the state of the distributed transaction might be
unknown or in doubt. In that case, Oracle stores the text specified by COMMENT
in the data dictionary along with the transaction ID. The text must be a
quoted literal up to 50 characters long. An example follows:COMMIT COMMENT 'In-doubt order transaction; notify Order Entry';
PL/SQL does not support the
FORCE clause, which, in SQL, manually commits an in-doubt distributed transaction. For example, the following COMMIT statement is not allowed:COMMIT FORCE '23.51.54'; -- not allowed
Undoing Changes with ROLLBACK
The
ROLLBACK statement ends the current
transaction and undoes any changes made during that transaction. Rolling
back is useful for two reasons. First, if you make a mistake like
deleting the wrong row from a table, a rollback restores the original
data. Second, if you start a transaction that you cannot finish because
an exception is raised or a SQL statement fails, a rollback lets you
return to the starting point to take corrective action and perhaps try
again.
Consider the example below, in which you insert
information about an employee into three different database tables. All
three tables have a column that holds employee numbers and is
constrained by a unique index. If an
INSERT statement tries to store a duplicate employee number, the predefined exception DUP_VAL_ON_INDEX is raised. In that case, you want to undo all changes, so you issue a rollback in the exception handler.DECLARE emp_id INTEGER; ... BEGIN SELECT empno, ... INTO emp_id, ... FROM new_emp WHERE ... ... INSERT INTO emp VALUES (emp_id, ...); INSERT INTO tax VALUES (emp_id, ...); INSERT INTO pay VALUES (emp_id, ...); ... EXCEPTION WHEN DUP_VAL_ON_INDEX THEN ROLLBACK; ... END;
Statement-Level Rollbacks
Before executing a SQL statement, Oracle marks an implicit
savepoint. Then, if the statement fails, Oracle rolls it back
automatically. For example, if an
INSERT statement raises
an exception by trying to insert a duplicate value in a unique index,
the statement is rolled back. Only work started by the failed SQL
statement is lost. Work done before that statement in the current
transaction is kept.
Oracle can also roll back single SQL statements to break
deadlocks. Oracle signals an error to one of the participating
transactions and rolls back the current statement in that transaction.
Before executing a SQL statement, Oracle must parse
it, that is, examine it to make sure it follows syntax rules and refers
to valid schema objects. Errors detected while executing a SQL
statement cause a rollback, but errors detected while parsing the
statement do not.
Undoing Partial Changes with SAVEPOINT
SAVEPOINT names and marks the current point in the processing of a transaction. Used with the ROLLBACK TO
statement, savepoints let you undo parts of a transaction instead of
the whole transaction. In the example below, you mark a savepoint before
doing an insert. If the INSERT statement tries to store a duplicate value in the empno column, the predefined exception DUP_VAL_ON_INDEX is raised. In that case, you roll back to the savepoint, undoing just the insert.DECLARE emp_id emp.empno%TYPE; BEGIN UPDATE emp SET ... WHERE empno = emp_id; DELETE FROM emp WHERE ... ... SAVEPOINT do_insert; INSERT INTO emp VALUES (emp_id, ...); EXCEPTION WHEN DUP_VAL_ON_INDEX THEN ROLLBACK TO do_insert; END;
When you roll back to a savepoint, any savepoints marked
after that savepoint are erased. However, the savepoint to which you
roll back is not erased. For example, if you mark five savepoints, then
roll back to the third, only the fourth and fifth are erased. A simple
rollback or commit erases all savepoints.
If you mark a savepoint within a recursive subprogram, new instances of the
SAVEPOINT
statement are executed at each level in the recursive descent. However,
you can only roll back to the most recently marked savepoint.
Savepoint names are undeclared identifiers and can be
reused within a transaction. This moves the savepoint from its old
position to the current point in the transaction. Thus, a rollback to
the savepoint affects only the current part of your transaction. An
example follows:
BEGIN SAVEPOINT my_point; UPDATE emp SET ... WHERE empno = emp_id; ... SAVEPOINT my_point; -- move my_point to current point INSERT INTO emp VALUES (emp_id, ...); EXCEPTION WHEN OTHERS THEN ROLLBACK TO my_point; END;
The number of active savepoints for each session is unlimited. An active savepoint is one marked since the last commit or rollback.
How Oracle Does Implicit Rollbacks
Before executing an
INSERT, UPDATE, or DELETE
statement, Oracle marks an implicit savepoint (unavailable to you). If
the statement fails, Oracle rolls back to the savepoint. Normally, just
the failed SQL statement is rolled back, not the whole transaction.
However, if the statement raises an unhandled exception, the host
environment determines what is rolled back.
If you exit a stored subprogram with an unhandled exception, PL/SQL does not assign values to
OUT parameters. Also, PL/SQL does not roll back database work done by the subprogram.Ending Transactions
A good programming practice is to commit or roll back
every transaction explicitly. Whether you issue the commit or rollback
in your PL/SQL program or in the host environment depends on the flow of
application logic. If you neglect to commit or roll back a transaction
explicitly, the host environment determines its final state.
For example, in the SQL*Plus environment, if your PL/SQL block does not include a
COMMIT or ROLLBACK
statement, the final state of your transaction depends on what you do
after running the block. If you execute a data definition, data control,
or COMMIT statement or if you issue the EXIT, DISCONNECT, or QUIT command, Oracle commits the transaction. If you execute a ROLLBACK statement or abort the SQL*Plus session, Oracle rolls back the transaction.
In the Oracle Precompiler environment, if your program
does not terminate normally, Oracle rolls back your transaction. A
program terminates normally when it explicitly commits or rolls back
work and disconnects from Oracle using the
RELEASE parameter, as follows:EXEC SQL COMMIT WORK RELEASE;
Setting Transaction Properties with SET TRANSACTION
You use the
SET TRANSACTION
statement to begin a read-only or read-write transaction, establish an
isolation level, or assign your current transaction to a specified
rollback segment. Read-only transactions are useful for running multiple
queries against one or more tables while other users update the same
tables.
During a read-only transaction, all queries refer to the
same snapshot of the database, providing a multi-table, multi-query,
read-consistent view. Other users can continue to query or update data
as usual. A commit or rollback ends the transaction. In the example
below, as a store manager, you use a read-only transaction to gather
sales figures for the day, the past week, and the past month. The
figures are unaffected by other users updating the database during the
transaction.
DECLARE daily_sales REAL; weekly_sales REAL; monthly_sales REAL; BEGIN ... COMMIT; -- ends previous transaction SET TRANSACTION READ ONLY NAME 'Calculate sales figures'; SELECT SUM(amt) INTO daily_sales FROM sales WHERE dte = SYSDATE; SELECT SUM(amt) INTO weekly_sales FROM sales WHERE dte > SYSDATE - 7; SELECT SUM(amt) INTO monthly_sales FROM sales WHERE dte > SYSDATE - 30; COMMIT; -- ends read-only transaction ... END;
The
SET TRANSACTION statement
must be the first SQL statement in a read-only transaction and can only
appear once in a transaction. If you set a transaction to READ ONLY, subsequent queries see only changes committed before the transaction began. The use of READ ONLY does not affect other users or transactions.Restrictions on SET TRANSACTION
Only the
SELECT INTO, OPEN, FETCH, CLOSE, LOCK TABLE, COMMIT, and ROLLBACK statements are allowed in a read-only transaction. Also, queries cannot be FOR UPDATE.Overriding Default Locking
By default, Oracle locks data structures for you
automatically. However, you can request specific data locks on rows or
tables when it is to your advantage to override default locking.
Explicit locking lets you share or deny access to a table for the
duration of a transaction.
With the
LOCK TABLE statement, you can explicitly lock entire tables. With the SELECT FOR UPDATE
statement, you can explicitly lock specific rows of a table to make
sure they do not change before an update or delete is executed. However,
Oracle automatically obtains row-level locks at update or delete time.
So, use the FOR UPDATE clause only if you want to lock the rows before the update or delete.Using FOR UPDATE
When you declare a cursor that will be referenced in the
CURRENT OF clause of an UPDATE or DELETE statement, you must use the FOR UPDATE clause to acquire exclusive row locks. An example follows:DECLARE CURSOR c1 IS SELECT empno, sal FROM emp WHERE job = 'SALESMAN' AND comm > sal FOR UPDATE NOWAIT;
The
SELECT ... FOR UPDATE
statement identifies the rows that will be updated or deleted, then
locks each row in the result set. This is useful when you want to base
an update on the existing values in a row. In that case, you must make
sure the row is not changed by another user before the update.
The optional keyword
NOWAIT tells Oracle not
to wait if requested rows have been locked by another user. Control is
immediately returned to your program so that it can do other work before
trying again to acquire the lock. If you omit the keyword NOWAIT, Oracle waits until the rows are available.
All rows are locked when you open the cursor, not as they
are fetched. The rows are unlocked when you commit or roll back the
transaction. So, you cannot fetch from a
FOR UPDATE cursor after a commit. (For a workaround, see "Fetching Across Commits".)
When querying multiple tables, you can use the
FOR UPDATE clause to confine row locking to particular tables. Rows in a table are locked only if the FOR UPDATE OF clause refers to a column in that table. For example, the following query locks rows in the emp table but not in the dept table:DECLARE CURSOR c1 IS SELECT ename, dname FROM emp, dept WHERE emp.deptno = dept.deptno AND job = 'MANAGER' FOR UPDATE OF sal;
As the next example shows, you use the
CURRENT OF clause in an UPDATE or DELETE statement to refer to the latest row fetched from a cursor:DECLARE CURSOR c1 IS SELECT empno, job, sal FROM emp FOR UPDATE; ... BEGIN OPEN c1; LOOP FETCH c1 INTO ... ... UPDATE emp SET sal = new_sal WHERE CURRENT OF c1; END LOOP;
Using LOCK TABLE
You use the
LOCK TABLE statement
to lock entire database tables in a specified lock mode so that you can
share or deny access to them. For example, the statement below locks
the emp table in row share mode.
Row share locks allow concurrent access to a table; they prevent other
users from locking the entire table for exclusive use. Table locks are
released when your transaction issues a commit or rollback.LOCK TABLE emp IN ROW SHARE MODE NOWAIT;
The lock mode determines what other locks can be placed on
the table. For example, many users can acquire row share locks on a
table at the same time, but only one user at a time can acquire an exclusive
lock. While one user has an exclusive lock on a table, no other users
can insert, delete, or update rows in that table. For more information
about lock modes, see Oracle9i Application Developer's Guide - Fundamentals.
A table lock never keeps other users from querying a
table, and a query never acquires a table lock. Only if two different
transactions try to modify the same row will one transaction wait for
the other to complete.
Fetching Across Commits
The
FOR UPDATE clause acquires
exclusive row locks. All rows are locked when you open the cursor, and
they are unlocked when you commit your transaction. So, you cannot fetch
from a FOR UPDATE cursor after a commit. If you do, PL/SQL raises an exception. In the following example, the cursor FOR loop fails after the tenth insert:DECLARE CURSOR c1 IS SELECT ename FROM emp FOR UPDATE OF sal; ctr NUMBER := 0; BEGIN FOR emp_rec IN c1 LOOP -- FETCHes implicitly ... ctr := ctr + 1; INSERT INTO temp VALUES (ctr, 'still going'); IF ctr >= 10 THEN COMMIT; -- releases locks END IF; END LOOP; END;
If you want to fetch across commits, do not use the
FOR UPDATE and CURRENT OF clauses. Instead, use the ROWID pseudocolumn to mimic the CURRENT OF clause. Simply select the rowid of each row into a UROWID variable. Then, use the rowid to identify the current row during subsequent updates and deletes. An example follows:DECLARE CURSOR c1 IS SELECT ename, job, rowid FROM emp; my_ename emp.ename%TYPE; my_job emp.job%TYPE; my_rowid UROWID; BEGIN OPEN c1; LOOP FETCH c1 INTO my_ename, my_job, my_rowid; EXIT WHEN c1%NOTFOUND; UPDATE emp SET sal = sal * 1.05 WHERE rowid = my_rowid; -- this mimics WHERE CURRENT OF c1 COMMIT; END LOOP; CLOSE c1; END;
Be careful. In the last example, the fetched rows are not locked because no
FOR UPDATE
clause is used. So, other users might unintentionally overwrite your
changes. Also, the cursor must have a read-consistent view of the data,
so rollback segments used in the update are not released until the
cursor is closed. This can slow down processing when many rows are
updated.
The next example shows that you can use the
%ROWTYPE attribute with cursors that reference the ROWID pseudocolumn:DECLARE CURSOR c1 IS SELECT ename, sal, rowid FROM emp; emp_rec c1%ROWTYPE; BEGIN OPEN c1; LOOP FETCH c1 INTO emp_rec; EXIT WHEN c1%NOTFOUND; ... IF ... THEN DELETE FROM emp WHERE rowid = emp_rec.rowid; END IF; END LOOP; CLOSE c1; END;
Doing Independent Units of Work with Autonomous Transactions
A transaction is a series of SQL statements that does a
logical unit of work. Often, one transaction starts another. In some
applications, a transaction must operate outside the scope of the
transaction that started it. This can happen, for example, when a
transaction calls out to a data cartridge.
An autonomous transaction is an independent transaction started by another transaction, the main transaction.
Autonomous transactions let you suspend the main transaction, do SQL
operations, commit or roll back those operations, then resume the main
transaction. Figure 6-1 shows how control flows from the main transaction (MT) to an autonomous transaction (AT) and back again.
Figure 6-1 Transaction Control Flow
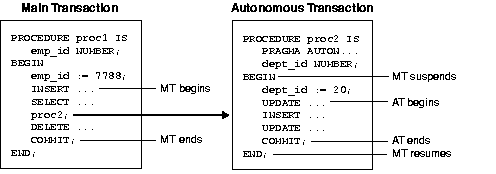
Text description of the illustration pls81028_transaction_control_flow.gif
Advantages of Autonomous Transactions
Once started, an autonomous transaction is fully
independent. It shares no locks, resources, or commit-dependencies with
the main transaction. So, you can log events, increment retry counters,
and so on, even if the main transaction rolls back.
More important, autonomous transactions help you build
modular, reusable software components. For example, stored procedures
can start and finish autonomous transactions on their own. A calling
application need not know about a procedure's autonomous operations, and
the procedure need not know about the application's transaction
context. That makes autonomous transactions less error-prone than
regular transactions and easier to use.
Furthermore, autonomous transactions have all the
functionality of regular transactions. They allow parallel queries,
distributed processing, and all the transaction control statements
including
SET TRANSACTION.Defining Autonomous Transactions
To define autonomous transactions, you use the pragma (compiler directive)
AUTONOMOUS_TRANSACTION. The pragma instructs the PL/SQL compiler to mark a routine as autonomous (independent). In this context, the term routine includes- Top-level (not nested) anonymous PL/SQL blocks
- Local, standalone, and packaged functions and procedures
- Methods of a SQL object type
- Database triggers
You can code the pragma anywhere in the declarative
section of a routine. But, for readability, code the pragma at the top
of the section. The syntax follows:
PRAGMA AUTONOMOUS_TRANSACTION;
In the following example, you mark a packaged function as autonomous:
CREATE PACKAGE banking AS ... FUNCTION balance (acct_id INTEGER) RETURN REAL; END banking; CREATE PACKAGE BODY banking AS ... FUNCTION balance (acct_id INTEGER) RETURN REAL IS PRAGMA AUTONOMOUS_TRANSACTION; my_bal REAL; BEGIN ... END; END banking;
Restriction: You cannot use
the pragma to mark all subprograms in a package (or all methods in an
object type) as autonomous. Only individual routines can be marked
autonomous. For example, the following pragma is not allowed:
CREATE PACKAGE banking AS PRAGMA AUTONOMOUS_TRANSACTION; -- not allowed ... FUNCTION balance (acct_id INTEGER) RETURN REAL; END banking;
In the next example, you mark a standalone procedure as autonomous:
CREATE PROCEDURE close_account (acct_id INTEGER, OUT balance) AS PRAGMA AUTONOMOUS_TRANSACTION; my_bal REAL; BEGIN ... END;
In the following example, you mark a PL/SQL block as autonomous:
DECLARE PRAGMA AUTONOMOUS_TRANSACTION; my_empno NUMBER(4); BEGIN ... END;
Restriction: You cannot mark a nested PL/SQL block as autonomous.
In the example below, you mark a database trigger as
autonomous. Unlike regular triggers, autonomous triggers can contain
transaction control statements such as
COMMIT and ROLLBACK.CREATE TRIGGER parts_trigger BEFORE INSERT ON parts FOR EACH ROW DECLARE PRAGMA AUTONOMOUS_TRANSACTION; BEGIN INSERT INTO parts_log VALUES(:new.pnum, :new.pname); COMMIT; -- allowed only in autonomous triggers END;
Autonomous Versus Nested Transactions
Although an autonomous transaction is started by another transaction, it is not a nested transaction for the following reasons:
- It does not share transactional resources (such as locks) with the main transaction.
- It does not depend on the main transaction. For example, if the main transaction rolls back, nested transactions roll back, but autonomous transactions do not.
- Its committed changes are visible to other transactions immediately. (A nested transaction's committed changes are not visible to other transactions until the main transaction commits.)
- Exceptions raised in an autonomous transaction cause a transaction-level rollback, not a statement-level rollback.
Transaction context
As Figure 6-2
shows, the main transaction shares its context with nested routines,
but not with autonomous transactions. Likewise, when one autonomous
routine calls another (or itself recursively), the routines share no
transaction context. However, when an autonomous routine calls a
non-autonomous routine, the routines share the same transaction context.
Figure 6-2 Transaction Context
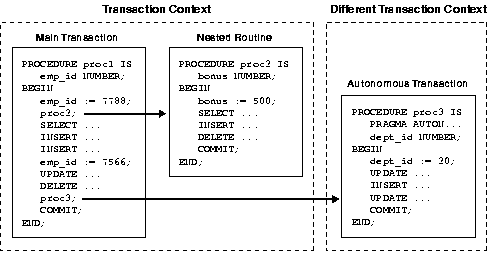
Text description of the illustration pls81029_transaction_context.gif
Transaction Visibility
As Figure 6-3
shows, changes made by an autonomous transaction become visible to
other transactions when the autonomous transaction commits. The changes
also become visible to the main transaction when it resumes, but only if
its isolation level is set to
READ COMMITTED (the default).
If you set the isolation level of the main transaction to
SERIALIZABLE, as follows, changes made by its autonomous transactions are not visible to the main transaction when it resumes:SET TRANSACTION ISOLATION LEVEL SERIALIZABLE;
Figure 6-3 Transaction Visibility
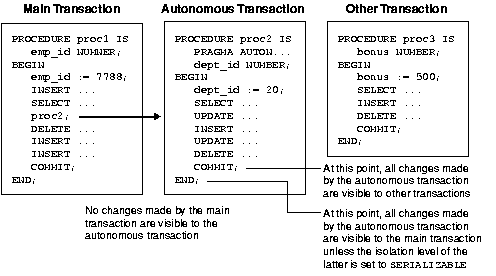
Text description of the illustration pls81030_transaction_visibility.gif
Controlling Autonomous Transactions
The first SQL statement in an autonomous routine begins a
transaction. When one transaction ends, the next SQL statement begins
another transaction. All SQL statements executed since the last commit
or rollback make up the current transaction. To control autonomous
transactions, use the following statements, which apply only to the
current (active) transaction:
COMMIT ends the current transaction and makes permanent changes made during that transaction. ROLLBACK ends the current transaction and undoes changes made during that transaction. ROLLBACK TO undoes part of a transaction. SAVEPOINT names and marks the current point in a transaction. SET TRANSACTION sets transaction properties such as read/write access and isolation level.
Note: Transaction properties
set in the main transaction apply only to that transaction, not to its
autonomous transactions, and vice versa.
Entering and Exiting
When you enter the executable section of an autonomous
routine, the main transaction suspends. When you exit the routine, the
main transaction resumes.
To exit normally, you must explicitly commit or roll back
all autonomous transactions. If the routine (or any routine called by
it) has pending transactions, an exception is raised, and the pending
transactions are rolled back.
Committing and Rolling Back
COMMIT and ROLLBACK end the active autonomous transaction but do not exit the autonomous routine. As Figure 6-4 shows, when one transaction ends, the next SQL statement begins another transaction.Figure 6-4 Multiple Autonomous Transactions
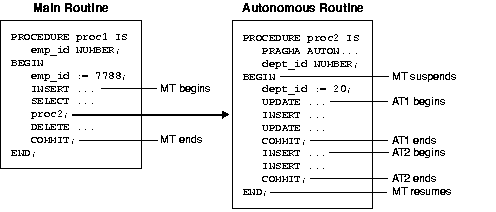
Text description of the illustration pls81031_multiple_autonomous_transactions.gif
Using Savepoints
The scope of a savepoint is the transaction in which it is
defined. Savepoints defined in the main transaction are unrelated to
savepoints defined in its autonomous transactions. In fact, the main
transaction and an autonomous transaction can use the same savepoint
names.
You can roll back only to savepoints marked in the current
transaction. So, when in an autonomous transaction, you cannot roll
back to a savepoint marked in the main transaction. To do so, you must
resume the main transaction by exiting the autonomous routine.
When in the main transaction, rolling back to a savepoint marked before you started an autonomous transaction does not roll back the autonomous transaction. Remember, autonomous transactions are fully independent of the main transaction.
Avoiding Errors
To avoid some common errors, keep the following points in mind when designing autonomous transactions:
- If an autonomous transaction attempts to access a resource held by the main transaction (which cannot resume until the autonomous routine exits), a deadlock can occur. In that case, Oracle raises an exception in the autonomous transaction, which is rolled back if the exception goes unhandled.
- The Oracle initialization parameter
TRANSACTIONSspecifies the maximum number of concurrent transactions. That number might be exceeded if autonomous transactions (which run concurrently with the main transaction) are not taken into account. - If you try to exit an active autonomous transaction without committing or rolling back, Oracle raises an exception. If the exception goes unhandled, the transaction is rolled back.
Using Autonomous Triggers
Among other things, you can use database triggers to log
events transparently. Suppose you want to track all inserts into a
table, even those that roll back. In the example below, you use a
trigger to insert duplicate rows into a shadow table. Because it is
autonomous, the trigger can commit inserts into the shadow table whether
or not you commit inserts into the main table.
-- create a main table and its shadow table CREATE TABLE parts (pnum NUMBER(4), pname VARCHAR2(15)); CREATE TABLE parts_log (pnum NUMBER(4), pname VARCHAR2(15)); -- create an autonomous trigger that inserts into the -- shadow table before each insert into the main table CREATE TRIGGER parts_trig BEFORE INSERT ON parts FOR EACH ROW DECLARE PRAGMA AUTONOMOUS_TRANSACTION; BEGIN INSERT INTO parts_log VALUES(:new.pnum, :new.pname); COMMIT; END; -- insert a row into the main table, and then commit the insert INSERT INTO parts VALUES (1040, 'Head Gasket'); COMMIT; -- insert another row, but then roll back the insert INSERT INTO parts VALUES (2075, 'Oil Pan'); ROLLBACK; -- show that only committed inserts add rows to the main table SELECT * FROM parts ORDER BY pnum; PNUM PNAME ------- --------------- 1040 Head Gasket -- show that both committed and rolled-back inserts add rows -- to the shadow table SELECT * FROM parts_log ORDER BY pnum; PNUM PNAME ------- --------------- 1040 Head Gasket 2075 Oil Pan
Unlike regular triggers, autonomous triggers can execute DDL statements using native dynamic SQL (discussed in Chapter 11). In the following example, trigger
bonus_trig drops a temporary database table after table bonus is updated:CREATE TRIGGER bonus_trig AFTER UPDATE ON bonus DECLARE PRAGMA AUTONOMOUS_TRANSACTION; -- enables trigger to perform DDL BEGIN EXECUTE IMMEDIATE 'DROP TABLE temp_bonus'; END;
For more information about database triggers, see Oracle9i Application Developer's Guide - Fundamentals.
Calling Autonomous Functions from SQL
A function called from SQL statements must obey certain rules meant to control side effects. (See "Controlling Side Effects of PL/SQL Subprograms".) To check for violations of the rules, you can use the pragma
RESTRICT_REFERENCES. The pragma asserts that a function does not read or write database tables or package variables. (For more information, See Oracle9i Application Developer's Guide - Fundamentals.)
However, by definition, autonomous routines never violate the rules "read no database state" (
RNDS) and "write no database state" (WNDS) no matter what they do. This can be useful, as the example below shows. When you call the packaged function log_msg from a query, it inserts a message into database table debug_output without violating the rule "write no database state."-- create the debug table CREATE TABLE debug_output (msg VARCHAR2(200)); -- create the package spec CREATE PACKAGE debugging AS FUNCTION log_msg (msg VARCHAR2) RETURN VARCHAR2; PRAGMA RESTRICT_REFERENCES(log_msg, WNDS, RNDS); END debugging; -- create the package body CREATE PACKAGE BODY debugging AS FUNCTION log_msg (msg VARCHAR2) RETURN VARCHAR2 IS PRAGMA AUTONOMOUS_TRANSACTION; BEGIN -- the following insert does not violate the constraint -- WNDS because this is an autonomous routine INSERT INTO debug_output VALUES (msg); COMMIT; RETURN msg; END; END debugging; -- call the packaged function from a query DECLARE my_empno NUMBER(4); my_ename VARCHAR2(15); BEGIN ... SELECT debugging.log_msg(ename) INTO my_ename FROM emp WHERE empno = my_empno; -- even if you roll back in this scope, the insert -- into 'debug_output' remains committed because -- it is part of an autonomous transaction IF ... THEN ROLLBACK; END IF; END;
Ensuring Backward Compatibility of PL/SQL Programs
PL/SQL Version 2 allows some abnormal behaviors that are no longer allowed. Specifically, Version 2 lets you:
- Make forward references to
RECORDandTABLEtypes when declaring variables - Specify the name of a variable (not a datatype) in the
RETURNclause of a function spec - Assign values to the elements of an index-by table
INparameter - Pass the fields of a record
INparameter to another subprogram asOUTparameters - Use the fields of a record
OUTparameter on the right-hand side of an assignment statement - Use
OUTparameters in theFROMlist of aSELECTstatement
For backward compatibility, you might want to keep this particular Version 2 behavior. You can do that by setting the
PLSQL_V2_COMPATIBILITY flag. On the server side, you can set the flag in two ways:- Add the following line to the Oracle initialization file:
PLSQL_V2_COMPATIBILITY=TRUE
- Execute one of the following SQL statements:
ALTER SESSION SET PLSQL_V2_COMPATIBILITY = TRUE; ALTER SYSTEM SET PLSQL_V2_COMPATIBILITY = TRUE;
If you specify
FALSE (the default), only the current default behavior is allowed.
On the client side, a command-line option sets the flag.
For example, with the Oracle Precompilers, you specify the run-time
option
DBMS on the command line.
No comments:
Post a Comment